





我们在做统计分析时,常常都习惯了这样的分析套路:先进行统计描述,然后做单因素分析,最后再进行多因素分析。在阅读文献时,我们也会发现,不管是一般的统计描述还是单因素分析,往往能够支持研究人员作出结论的,还是要看最终的多因素分析结果。
在前期推送的内容中我们也讲过,多因素分析的目的是通过控制其它多个混杂因素的影响,找出具有独立作用的影响因素,并估计其效应大小。
既然这样的话,做单因素分析还有什么用呢,直接做多因素分析不就好啦?
多因素分析的地位固然重要,但是单因素分析也必不可少,单因素分析可以为多因素分析提供很多有效的信息,将单因素和多因素分析的结果进行比较,也能发现很多问题。如果单因素和多因素分析的结果一致的话,结论就比较稳定且容易解释,但是我们常常会遇到单因素和多因素分析的结果不一致,甚至是出现相互矛盾的尴尬情况,此时又该怎么办,该如何去解释呢?
今天我们就来一起聊一聊单因素分析和多因素分析之间的爱恨情仇。
首先我们根据单因素分析和多因素分析的结果对比,将可能出现的情况做一个四格表,如表1所示,分为A、B、C、D一共4种情况,下面我们分别对这四种情况进行讨论。
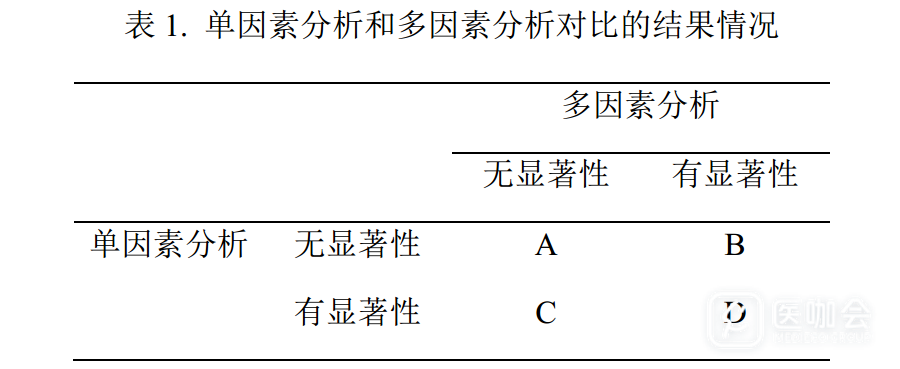
情况A
单因素分析和多因素分析的结果都显示无统计学显著性,两者结果一致,均为阴性结果
在这种情况下,结果还是相对比较好解释的,一般基本上可以认为该因素对于结局事件来说,不是一个有意义的影响因素。
但是事情也并非这么简单,如果该因素作为一个混杂因素,在多因素分析中只是用来起到调整混杂作用的目的,那么虽然它在单因素和多因素分析中都是阴性结果,可能也不会太引起研究人员的重视;但是如果该因素是研究中所重点关注的一个因素,例如暴露/处理因素,此时单因素和多因素分析都得出阴性结果的话,就会让人感觉比较沮丧,不过也更值得我们好好去思考一下阴性结果背后的意义。










确认删除