在实际工作中,通常需要收集众多变量以全面分析问题。然而,变量增多意味着需要更大的样本量和更复杂的模型,且可能引发变量间的严重多重共线性。为了充分有效地利用数据,人们希望用较少的新指标代替原来较多的旧变量,同时要求这些新指标尽可能地反映原始变量的信息。主成分分析和因子分析正是解决此类问题的有效方法,它们能够充分提取变量信息,减少分析变量个数,从而使问题更加简单直观,数据更加容易进行分析和处理。
举个简单例子,假设一个百万人的大型公司要对某项改革措施征询所有员工的意见,在传统的纸质函询时代,对每一个人都询问一遍显然太过费事,如果能对一部分具代表性的人进行询问,结果既具代表性又具高度可行性。在这个过程中有两个关键点:一是被询问的部分人群如何尽可能代表这百万人的意见,如果代表性不强,那么结果会存在较大偏差。二是被询问的人数如何尽可能的少,如果还要调查50万人,那么显然工作量并未显著降低,如果调查1万人,甚至1000人就可以,那实际操作性明显高多了!主成分分析的核心其实就体现在这个信息浓缩过程中,如何保障信息少丢失、又使提取的变量不要过多?
一、基本原理
假设X1、X2两个变量之间存在高度共线性,用散点图表示其关系如图所示。
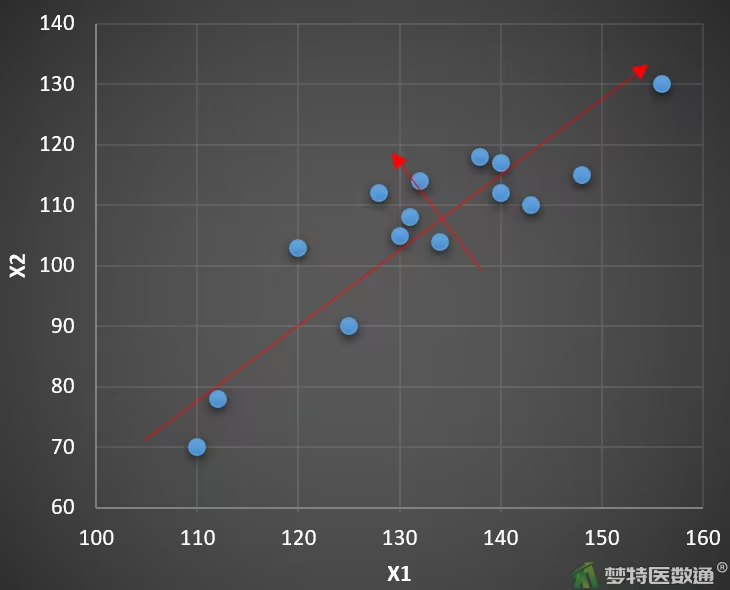
显然,两个变量之间存在明显相关性,如果直接将它们纳入模型,将难以避免多重共线性问题。要多这两个变量进行信息浓缩,其本质就是处理数据变异。在图中,散点构成了一个明显的椭圆形,该椭圆长轴方向上数据的变异明显大于短轴方向。沿着椭圆的长短轴方向设定一个新的坐标系,如图红线所示,则新产生的这两个变量和原始变量间存在着数学换算关系。但是这两个新变量彼此不相关,且信息量的分布显然不同:长轴方向上的变量携带了大部分数据的变异信息,而短轴方向上的变量只携带了一小部分变异信息。此时,只需使用长轴方向上的新变量,就可代表原先两个变量的大部分信息,从而达到了降维的目的。显然,两变量间的相关性越强,椭圆的长短轴就相差得越大,降维则越有价值。
二、前提条件
1. 原始数据的变量足够多。
2. 原始数据各变量之间的共线性或相关关系较强,如果原始变量之间的线性相关程度很小,它们之间不存在简化的数据结构,这时进行主成分分析实际上是没有意义的。
三、主成分分析的应用
主成分分析是一种特征提取的方法。PCA主要用于解决信息浓缩问题,也应用于发现数据中的基本结构,即数据中变量之间的关系。PCA往往是大型研究中的中间环节,也用于发现其他啊机器学习方法的前处理。最典型的应用为:(1)主成分评价;(2)主成分回归
四、优缺点
(一) 优点
- 仅仅需要以方差衡量信息量,不受数据集以外因素的影响。
- 各主成分之间正交,可消除原始数据成分间相互影响的因素。
- 计算方法简单,主要运算是特征值分解,易于实现。
(二) 缺点
- 主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
- 方差小的非主成分也可能含有重要信息,因降维丢弃可能对后续数据处理有影响。
来源:【梦特医数通】