系统评价要评估研究的偏倚风险,ChatGPT能做吗?
对纳入的RCT进行偏倚风险评估是系统评价作者的关键任务之一。麦克马斯特大学的CLARITY小组创建了 Cochrane偏倚风险工具的改进版,该工具已被广泛应用于众多高质量的系统评价中。
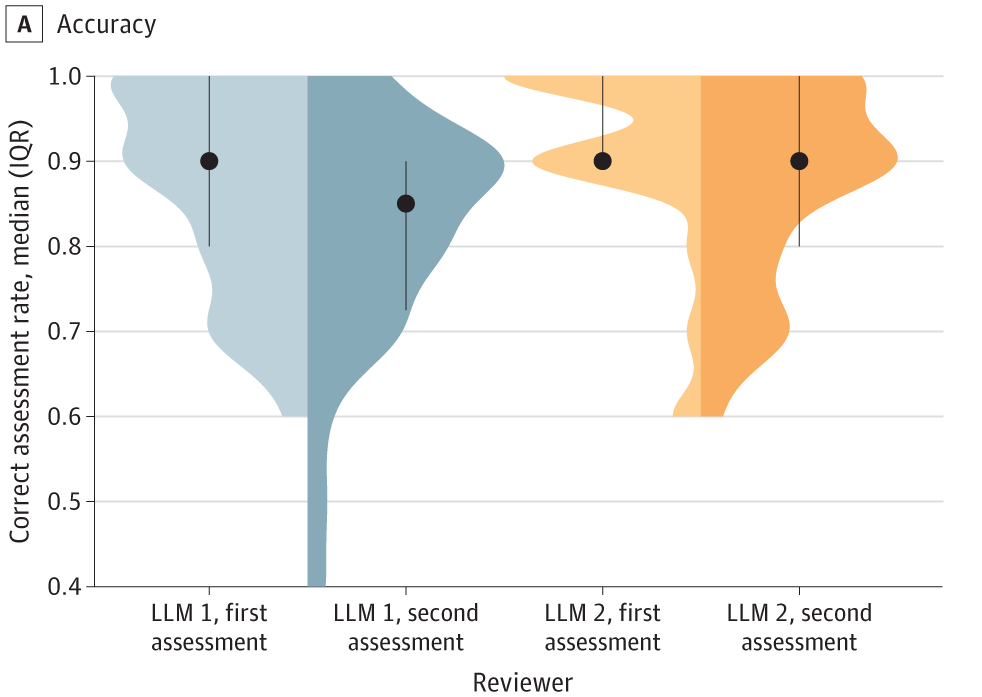
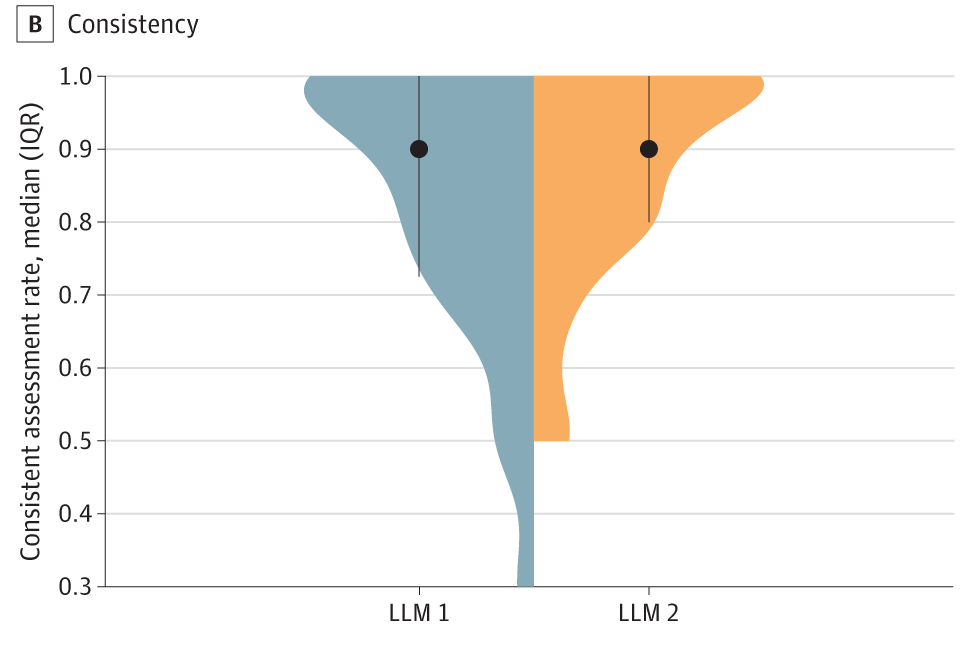
JAMA Network Open近期发表了一篇文章,开发了一个结构化提示来指导2 个大语言模型(ChatGPT和Claude)使用CLARITY小组创建的Cochrane偏倚风险工具,评估 30 项随机对照试验(RCT)的偏倚风险。
关于Cochrane偏倚风险工具的介绍,以及对大语言模型(LLM)的提示语,详见附件文档。
结果显示,LLM 1 和 LLM 2 均表现出良好的准确性,LLM 1 的平均正确评估率为 84.5%,LLM 2 的正确评估率略高,为 89.5%。研究表明大语言模型有可能成为系统评价过程中的有利工具。