
本文内容来自《中华流行病学杂志》2024年第40卷第1期,原题目为《效应修饰作用分析方法与案例解析系列(一):流行病学和经典Meta分析中的效应修饰》。将这篇文章分享给医咖会的伙伴们,希望大家能从领域大咖的见解中有所收获,指导医学研究之路。(感谢作者授权)
效应修饰作用(EM)是指干预措施与结局的关联或效应在某个第三因素的不同水平中存在差异,该第三因素被称为EM因子[1]。在统计分析中,EM实际上是指干预措施与协变量的交互作用[2]。在流行病学研究中,EM主要体现为某种干预/暴露因素在不同特征的人群中产生的效应不同,即此EM因子“修饰”了该干预/暴露因素的效应。
在流行病学研究中,研究人群往往或多或少存在着一定的异质性,在系统综述和Meta分析中异质性则更大,研究者则需要考虑所关注的关联是否受到了这些异质性因子的修饰。想要探究EM,则需要深入了解在不同场景下EM因子对结果产生的影响,并选择对应的统计分析方法。
基本原理
1. EM及其研究意义
(1)EM及其分类:临床研究中最常见的EM因子是研究对象的基线特征,例如年龄、性别、疾病严重程度等[3]。在这种情况下,EM源自所研究人群某特征基线水平差异和暴露因素之间复杂的生物学机制。例如,某种药物在男性和女性患者中所产生的效应存在显著差异,这可能是由于该药物的药理机制受到性激素的影响[4]。
EM可以按照对关联的影响分为定量EM和定性EM。定量EM是指在不同EM因子水平下,关联的强度不同。例如,在图1的亚组1中,男性和女性的某一结局均OR>1.00,但二者的OR值大小存在明显差异。定性EM是指在不同EM因子水平下,关联的方向相反,或所研究的干预在某一EM因子水平下与结局存在关联,而在另一EM因子水平下不存在关联[4]。例如,在图1的亚组2中,城镇居民的OR>1.00,而农村居民的OR值的95%CI跨过了1.00,说明存在定性EM。
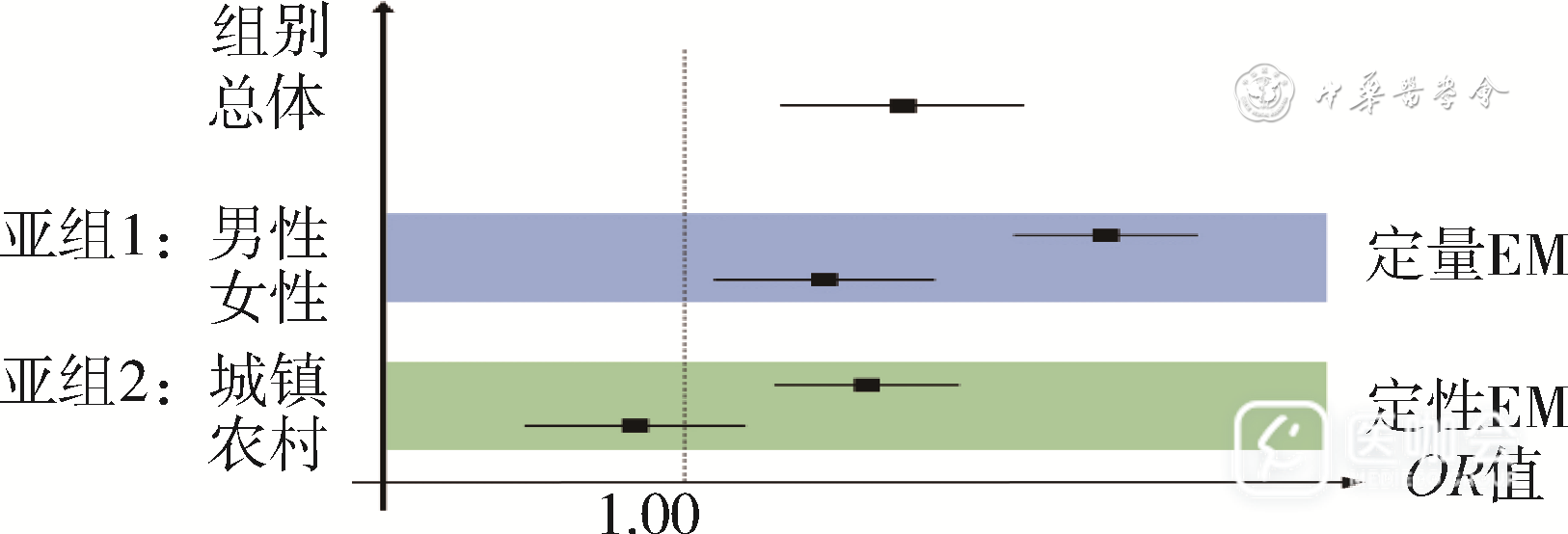
图1 效应修饰作用(EM)的分类:定量与定性
另外,EM可根据度量方式分为加性度量和乘性度量。加性度量指风险差尺度上暴露使结局风险增加或减少了多少,加性EM指不同EM因子水平之间差异效应值(即绝对效应值)不相等;乘性度量指风险比尺度上暴露使结局风险增加了几倍或减少了多少,乘性EM指不同EM因子水平之间比值效应值(即相对效应值)不相等[4]。以表1的模拟数据为例,在探究某一暴露因素与结局风险的关联时,进行亚组分析后发现,男性暴露组的结局事件发生率为40%,未暴露组的发生率为10%,女性中暴露组和未暴露组的发生率分别为80%和50%。在加性度量上,男性组的风险差为40%-10%=30%,女性组的风险差为80%-50%=30%,层间效应差为30%-30%=0,因此认为性别在该暴露因素与结局的关联中不存在EM;而在乘性度量上,男性的风险比为40%/10%=4.0,女性组的风险比为80%/50%=1.6,层间的效应比为4.0/1.6=2.5,认为性别在该关联中存在EM。因此,在报告EM时,应清晰说明具体的效应度量方式[1]。
表1 效应修饰作用的分类:加性度量与乘性度量
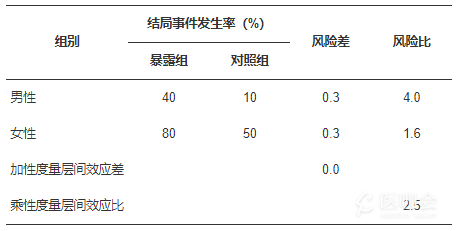
组别结局事件发生率(%)风险差风险比暴露组对照组男性40100.34.0女性80500.31.6加性度量层间效应差0.0乘性度量层间效应比2.5
EM也常被称为交互作用,交互作用的解释:当研究中存在两个或两个以上自变量时,其中一个自变量的效果在另一个自变量不同水平上表现不一致的现象,即某一因素的真实效应随着另一因素的改变而改变[1]。需要注意的是,当交互作用存在时,单纯研究某个因素的作用没有意义,必须分别探讨每个因素在另一个因素不同水平上对结局的作用模式[3]。对应上述的风险度量方式,交互作用也可分为相加交互作用和相乘交互作用。
(2)EM的研究意义:首先,忽略EM可能会获得不精确甚至有偏差的结果。在前述的模拟案例中(图1中的亚组2),如果忽略城镇和农村的差异,仅以总体的效应值作为结论,则将该结论外推到实际临床应用时,该效应值可能既不适用于城镇人群,也不适用于农村人群。此外,关注该临床问题的其他研究也可能由于人群中城镇和农村居民比例的不同而得出不同的效应值。因此,在这种情况下,忽略EM不仅导致研究结果有偏,还会导致“该干预措施仅在城镇人群中有效”这一重要证据的丧失。
从流行病学的宏观角度来看,探究EM有助于发现高危人群或治疗敏感群体,从而实现精准预防或治疗。从药物流行病学的角度来看,探究EM可以获得药物在不同人群中的疗效,并发现更多深入的证据,对于个体化的临床药物选择和指南制订具有重要意义[3]。因此,当研究者评估流行病学因果效应时,应考虑该效应是否存在可能的EM,对怀疑的EM因素进行识别和估计,并报告不同EM因素水平下的效应结果。
2. EM与混杂效应的关系:需要注意的是,EM与混杂效应是两个完全不同的概念。首先从概念上,混杂因素指的是存在一个与研究因素和结局都有关的外部因素,它不是二者因果链上的中间变量,会使得研究因素和结局之间的真实关联被歪曲。而EM则是由于某个外部因素的水平差异,使研究因素和结局之间的关联发生了真实的改变[5]。在统计学上,二者对结局产生影响的本质不同。在某些研究中,混杂因素和EM因子被统称为“预后变量”,即会对结局产生影响的变量。混杂因素对结局的影响表现为扭曲了该干预措施对结局的效应,而EM则表现为EM因子与所研究干预措施的交互效应。
在分析方法上,二者都可以通过亚组分析(或称为分层分析)来识别。对于EM因子来说,分层后各层效应值不同,且总效应值与各层效应值的加权平均值相近[5],见图2A,所研究的干预措施在女性亚组中效应明显更强,总体效应值在两个亚组效应值之间。而对于混杂因素来说,分层后各层效应值之间不存在差异,并且各层效应值可能分布在总效应值的同侧或两侧,考虑年龄是一种混杂因素,因各比较组之间年龄分布不同,使得干预措施的效应被高估了,见图2B。
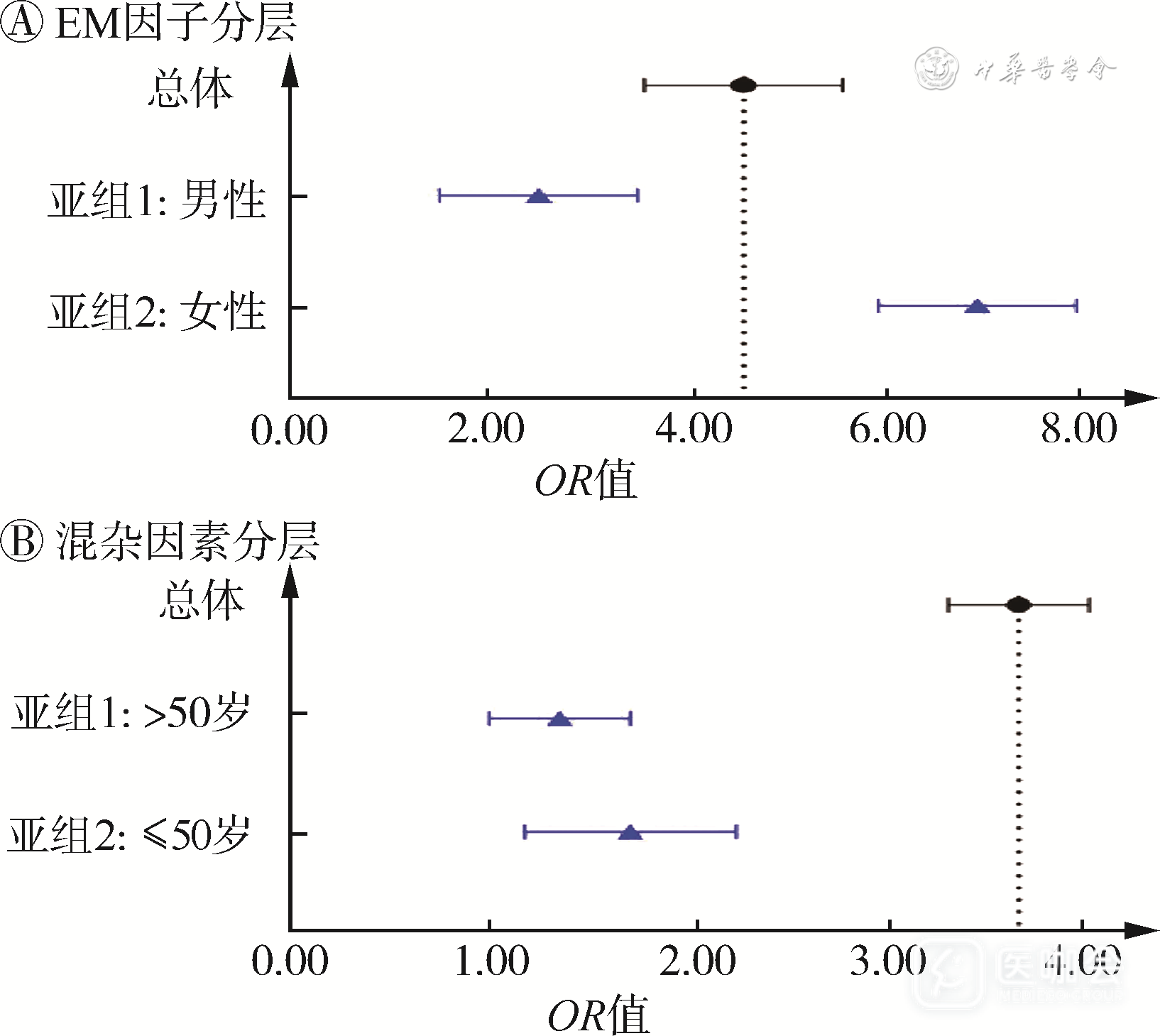
图2 效应修饰作用(EM)因子与混杂因素的亚组分析示例
在研究目标方面,混杂是一种偏倚,重点在于通过研究设计或分析将其控制,甚至消除。而EM的重点在于识别、详细描述、报告,以及临床意义的解读和应用[2]。在实际研究中,应将EM因子与混杂因素进行区分。同时,一个因子可能既是与结局相关的混杂因素,又是与暴露存在交互的EM因子,在这种情况下,应将该因子对结局的单因素混杂作用和其与暴露因素交互的EM分开进行探究,若采用回归模型的方法,EM表现为该EM因子与暴露因素交互项的回归系数。
3. EM在原始研究和Meta分析中的规范化描述
(1)原始研究:在进行原始研究时,研究者通常采用亚组分析来识别潜在的EM因子。为了确定某一因子是否修饰了暴露与结局的效应,需要在该因子的每个水平下计算暴露与结局的效应,并根据实际研究问题选择加性或乘性度量。如果不同水平之间的效应量不同,则认为该因子存在EM。研究者应根据研究的具体基本情况,结合既往研究和生物学证据,遴选出可能存在EM因子。此外,还可以通过构建多因素回归模型,将研究者怀疑的EM因子与暴露因素作为交互项引入,通过对交互项回归系数的假设检验来判断该EM是否存在。
随机对照试验(RCT)被认为是获得临床干预措施效果无偏估计的“金标准”[6]。在RCT研究中,受试者被随机分入试验组或对照组。通过随机分组,各组人群的基线特征基本一致,各潜在EM因子的分布不存在明显差异。在某些RCT的探索性亚组分析中,研究者可能会发现药物在不同亚组人群中的效应不同,且某些亚组的效应值与RCT的总体效应值存在差异,这往往是由于研究人群中某些特征的分布情况导致的,例如:某种药物在女性患者中疗效较强,在男性患者中疗效较弱,如果RCT人群中女性占比高,则得出的整体效应值可能更接近女性患者中的较强效应值。这提示研究者在下结论时应谨慎限定人群特征,但并不影响RCT组间的可比性,也不影响该RCT结果的准确性,所得出的结果仍然可认为是该RCT人群总体中干预措施效应的无偏估计。
(2)Meta分析:基于RCT研究进行的系统综述/Meta分析所获得的结果在证据分级系统中被看作是最高等级的证据[7]。经典Meta分析是将研究某一临床问题的多个RCT的结果进行合并,这一过程基于“同质性假设”,即认为在不同RCT中,同一干预措施疗效比较的效应值应该是近似一致的,效应值差异由随机误差导致[8]。虽然单个RCT可以通过“随机化”实现组间人群基线分布的均衡,但在进行系统综述/Meta分析时,研究同一临床问题的多个RCT往往因为各自纳入排除标准的不同,导致研究人群的基线特征存在差异[9]。这些基线特征可能在干预措施和结局的关联中起到EM,在Meta分析中体现为临床异质性。
在同质性假设的前提下,人群基线特征是否存在EM,以及EM的强弱、EM因子的研究间分布差异,均可能影响Meta分析结果的准确性[10],研究者同样需要通过亚组分析等方法对可能的EM因子进行识别。
Meta分析中可能出现的EM可总结为4种场景:①当研究中不存在任何EM因子时,在基线指标不同水平的患者中,干预组与对照组的相对效应值始终保持一致。此时,即使原始RCT人群间存在基线特征分布差异,Meta分析中的异质性也很小,可以采用固定效应模型对结局效应值进行加权合并,合并效应值的准确性较高(图3A)。②当存在较弱的EM时,不同基线特征水平对结局效应值的影响较小,可以忽略EM的影响。此时,Meta分析的合并效应值仍然准确可靠(图3B)。③当存在较强的EM,但该因子在研究间的分布差异不大(RCT的人群特征较为相似)时,研究间异质性也较小,可以采用固定效应模型进行合并(图3C)。④当存在较强的EM且EM因子在研究间的分布差异较大时,研究间异质性较大,若盲目按同质性假设进行合并,合并效应值的准确性和精确性可能均不佳,还可能得到有偏结果[11],此时需要对EM进行详细分析(图3D)。
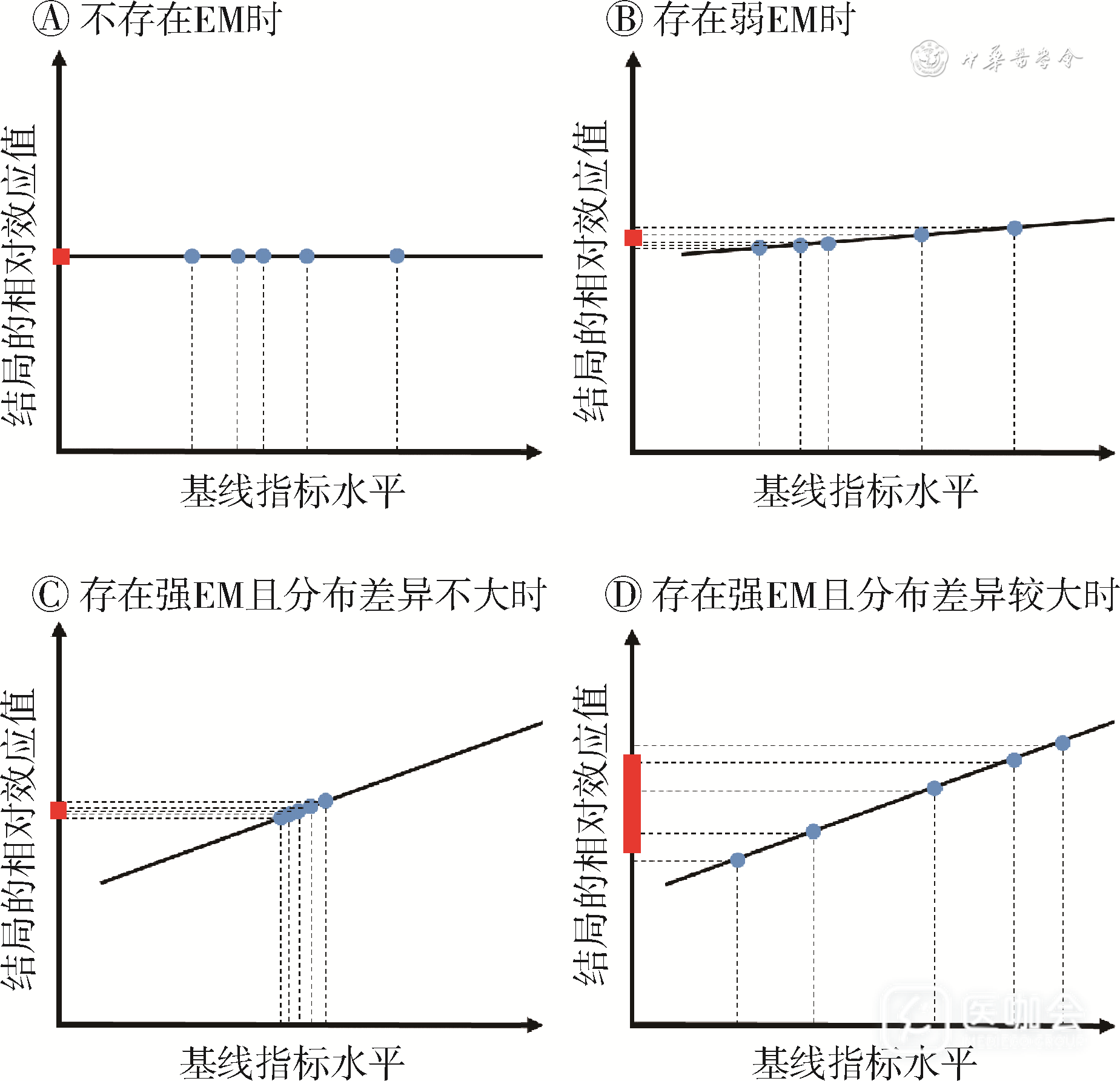
图3 不同效应修饰作用(EM)场景下Meta分析的合并效应情况
注: 每个蓝点代表一个RCT研究,红色方块表示Meta分析的加权平均结果,即为每个蓝点纵坐标值的加权平均
当Meta分析研究中存在较强EM因子,并且该因子在原始研究的人群间存在分布差异时,需要对该EM因子的作用进行深入探讨。如果仅采取传统的Meta分析方法直接合并数据,忽视“所研究的干预措施可能在不同基线人群中具有不同疗效”这一重要临床信息,可能会得到置信区间极宽且有偏的效应值[12]。2020年一项研究深入探究了Meta分析中人群基线特征作为EM因子对药物的疗效评价所产生的影响,该研究以银屑病各种药物的疗效比较为例,对所有纳入研究进行了Meta分析,并根据4个基线特征对纳入的研究进行了4次亚组分析。结果显示,亚组分析的异质性均比总体Meta分析更低,所得出的结果与总体结果存在差异[13]。该研究提示在进行Meta分析时应重视原始研究间的人群特征差异,并关注其可能对结局产生的EM,避免直接汇总所造成的结果偏差。见图4。
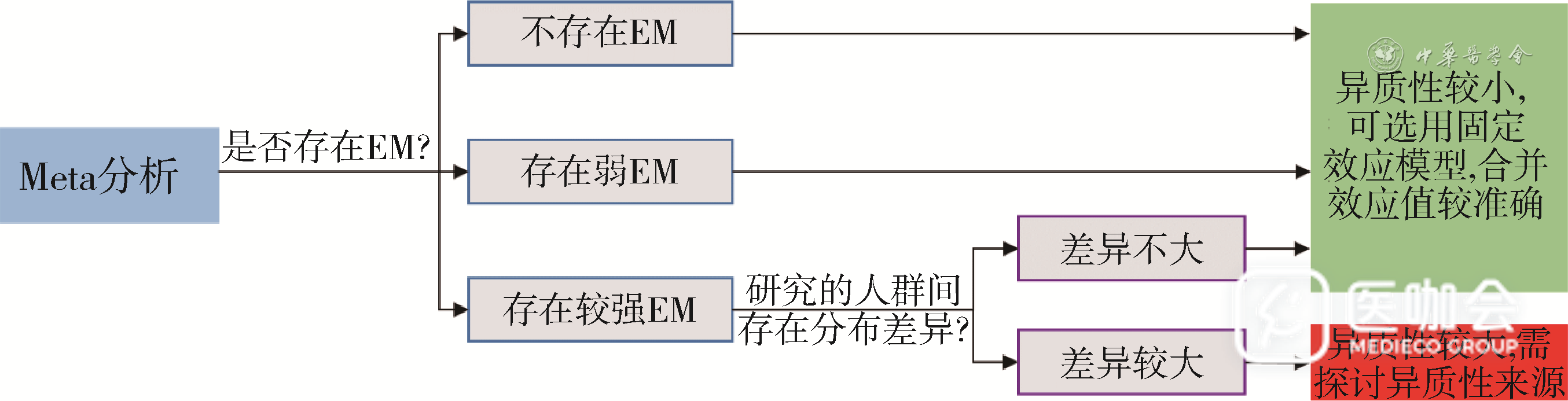
图4 Meta分析中可能出现的效应修饰作用(EM)场景及决策
4. 经典Meta分析中的EM分析策略:经典Meta分析常用亚组分析和Meta回归这2种方法探究EM。亚组分析将人群按照某一因素的不同水平分组,分别计算暴露与结局的关联指标,并对组间的效应值进行比较或一致性检验,以确定该因素是否为EM因子。回归分析则通过构建回归模型,将潜在的EM因子与暴露的交互项引入,通过对其回归系数的假设检验来判断是否存在EM[14]。










确认删除