





在介绍倾向性分析方法之前,我们先介绍一个非常重要的概念:倾向性评分。顾名思义,倾向性评分是指在一定协变量条件下,一个观察对象接受某种暴露/处理因素的可能性,它是一个从0到1的范围内连续分布的概率值。
其基本原理是将多个混杂因素的影响用一个综合的倾向性评分来表示,从而降低了协变量的纬度,减少了自变量的个数,有效的克服了分层分析和多因素调整分析中要求自变量个数不能太多的短板。
那么在进行倾向性分析之前,第一步就是要计算出每个研究对象的倾向性评分。倾向性评分的估计是以暴露/处理因素作为因变量Y(0或1),其他混杂因素作为自变量X,通过建立一个回归模型来估计每个研究对象接受暴露/处理因素的可能性,最为常用的是logistic回归模型。
用logistic回归模型估计倾向性评分,操作简单容易实现,可以直接得到倾向性评分分值,结果也易于理解。倾向性评分越接近于1,说明患者接受某种暴露/处理因素的可能性更高,越接近于0,说明患者不接受任何暴露/处理因素的可能性更大。
在观察性研究中,通过倾向性评分来调整组间个体的差异,除了暴露/处理因素和结局变量分布不同外,可认为其他混杂因素都均衡可比,相当于进行了“事后随机化”,使观察性研究的数据达到近似随机分配的效果。
目前应用倾向性评分来控制混杂因素的方法主要有四种,下面我们将一一向大家进行介绍。
一、倾向性评分匹配法
在观察性研究中,如病例对照研究,经常会见到匹配的概念,即按照某些因素或特征,将病例组(或暴露组)和对照组的研究对象进行匹配,以保证两组研究对象具有可比性,从而排除匹配因素的干扰。
同样,既然倾向性评分是一个能够反映多个混杂因素影响的综合评分,我们也可以将两组人群按照倾向性评分从小到大来进行匹配,仅用匹配倾向性评分一个指标来达到同时控制多个混杂因素的目的。倾向性评分匹配是倾向性分析中应用最为广泛的一种方法。
首先我们要计算出每一个研究对象的倾向性评分,然后从小到大进行排序,对于每一个暴露/处理组的研究对象,从对照组中选取与其倾向性评分最为接近的所有个体,并从中随机抽取一个或N个研究对象作为匹配对象,直至所有的研究对象均匹配完毕,未匹配上的研究对象则进行舍去。
(倾向性评分匹配的具体软件操作过程:SPSS操作:轻松实现1:1倾向性评分匹配;SPSS详细操作:1:n倾向性评分匹配)
当然,有多少研究对象可以成功匹配,常常与选择匹配的比例和匹配的标准有关。匹配的比例最常见的为1:1匹配,需要根据两组人群的数量来决定合适的匹配比例,建议不要超过1:4匹配。
对于匹配标准,如果匹配的标准很高,则能够成功匹配的对象就可能会少,甚至出现匹配不上的现象,造成研究对象信息的浪费,如果匹配的标准很宽泛,则匹配的效果就会较差,有可能出现两组人群在匹配后依然存在混杂因素分布不均衡的现象。
例如某个个体的倾向性评分为0.8,如果设定匹配标准为±0.02,则需要为其寻找倾向性评分在0.78-0.82之间的对照进行匹配,匹配范围太窄就可能出现匹配不上的情况;如果设定匹配标准为±0.2,则需要为其寻找倾向性评分在0.8-1.0之间的对照进行匹配,匹配范围太宽则可能降低匹配的效果。
我们用上一篇讲解多因素调整法时所引用的研究作为实例进行讲解。该研究一共纳入了122124名名研究对象,其中有60%的患者(73238)在住院30天内接受了心脏介入治疗,40%的患者(48886)接受了保守治疗,两组人群基线特征分布很不均衡(表1)。

为了控制混杂因素的影响,研究人员采用倾向性评分匹配的方法,以倾向性评分±0.1、年龄±5岁为标准进行匹配,最终共成功匹配31193组研究对象,其基线特征比较也基本达到了均衡,如表2所示。
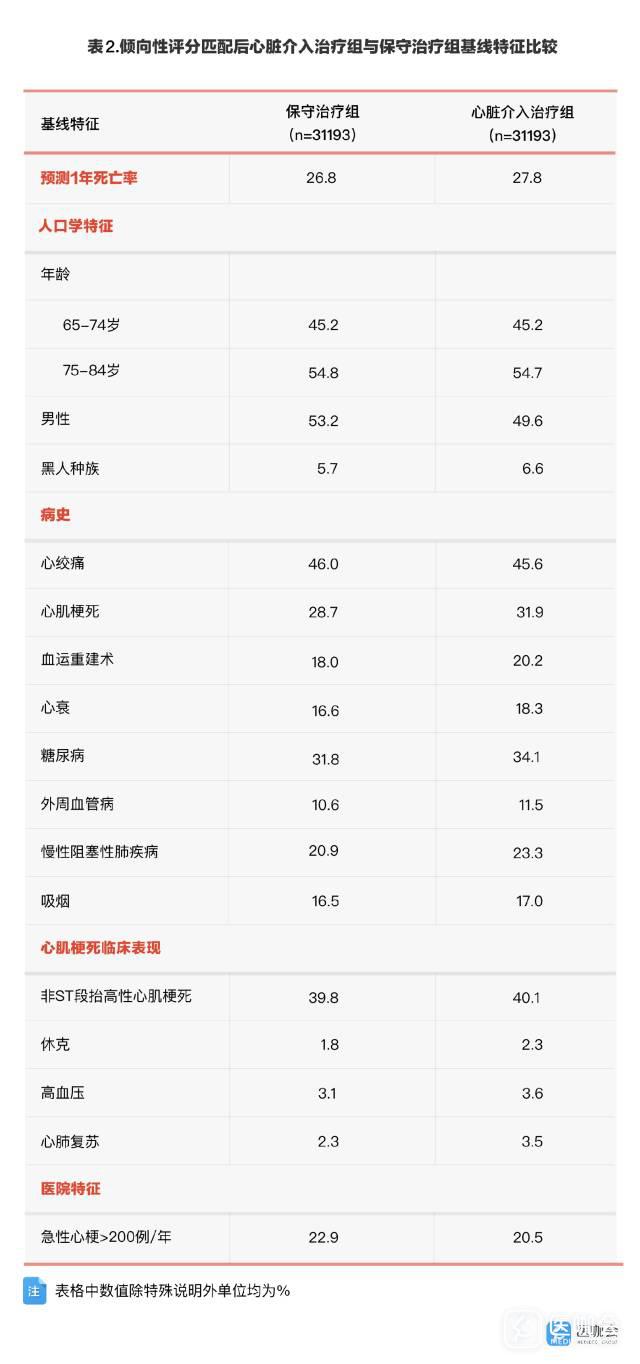
以此计算的HR=0.53(95% CI:0.51-0.54),提示心脏介入治疗可以有效降低心梗患者47%的死亡相对风险,与多因素调整法计算的HR=0.51(95% CI:0.50-0.52)结果基本一致。










确认删除