
本文转载自:张天嵩,董圣杰,杨智荣,武珊珊,田金徽,孙凤*. 网络Meta分析研究进展系列(十三):生存数据的网络Meta分析[J]. 中国循证心血管医学杂志. 2021;13(6):649-652
感谢《中国循证心血管医学杂志》和孙凤教授授权医咖会转载。
在生物医学领域,有很多研究感兴趣的结局是到某个事件发生的时间,发生的事件可以是不利结果(如死亡、肿瘤复发等)、有益结果(如怀孕、出院等)、中性结果(如停止母乳时间)",这类数据称为至事件时间数据(time-to-event data),传统上称为生存数据或生存资料 (survival data)、随访资料(follow-up data)。
对该类数据行的统计分析称为生存分析,主要考察每个研究对象出现某一结局所经历的时间,广泛应用于恶性肿瘤、慢性疾病等随访研究中事件分析,比如疾病的发生、复发、转移、伤口的愈合、某种症状的消失等。
生存数据具有独特的特点:①至事件发生的时间趋向于偏态分布,则采用正态似然不适合;②在随访期内并非每例患者都出现待观察的事件,即有截尾观测。
在生存数据中,结局事件和发生时间同等重要,主要的分析方法为风险或生存函数。针对生存数据进行经典的Meta分析和网络Meta分析(network meta-analysis, NMA),与连续型数据和二分类数据相比更加棘手,既不能简单地将时间作为连续型数据处理,也不能把事件简单地作为二分类数据处理。
生存数据NMA,一般可分为一步法和两步法两种分析策略,一步法适用个体参与者数据(individual participant data,IPD);两步法适用于IPD和聚合数据(aggregate data,AD),目前多使用两步法。
本文主要梳理基于两步法生存数据NMA的相关方法和模型,以期为研究人员了解和开展相关工作提供参考。
1、生存数据类型
1.1 个体参与者数据
理想情况下,系统评价员能够获得纳人NMA每个原始研究的IPD,收集到原始研究的起点事件和终点事件及相关人数、生存时间、影响因素(协变量)等。IPD既直接用于一步法NMA建模;也可采用适合的模型计算出单个研究的尺度参数和位置参数,然后进行NMA效应量合并。
1.2 聚合数据
如果不能获得原始研究的IPD,则需要依赖于研究水平的聚合数据如相应的概括统计量(summary statistics)。一般情况下,报告的生存数据效应指标多为生存率、生存期、生存风险比/危险比(Hazard ratio,HR)等。
其中,生存率指标主要有总生存率(overall survival,OS)和无进展生存率(progression-free survival,PFS)等,有时也会报告在某个时间点患者存活比例(时点生存率)等;生存期指标主要有平均生存期、中位生存期、无病存活期、无“事”存活期(event free survival,EFS)等。
但在实践中,HR是用来比较不同组别至事件时间干预效应最常用、最合适的指标,但遗憾的是有不少研究并未直接报告HR,但可以通过其他统计量转换或从Kaplan-Meier (K-M)曲线中提取来获得,计算HR及其方差的主要方法如表1所示。
表1. HR及其方差的计算方法

2、效应量计算
在系统评价和Meta分析中,生存数据最合适的效应量是HR,如果不能获得IPD,则需要小心采用相应方法从研究中水平来获得HR及相应统计量,本文重点讨论从概括统计量转换或从K-M曲线中估算HR。
2.1 时序检验
Tierney等[1]提供了基于研究的报告信息如何从单个研究中计算HR及相应统计量,并给出大量公式、详细解释、实用例子和基于 Excel开发的计算工具,非常有参考意义。
例如,假设能从时序检验(log-rank test)获得实验组相对于治疗组的lnHR可通过(O-E)/V来估计,标准误为1/√V。式中O为每个研究中实验组事件发生数,E为实验组期望发生事件数,(O-E)为log-rank统计量,V为log-rank统计量的方差。
一项新辅助化疗治疗口咽癌研究的时序检验结果如表2所示,则根据公式很容易的获得HR的对数及相应方差或标准误,分别为:

2.2 Cox比例风险回归模型
在纳人Meta分析的随机对照或队列研究中,常用Cox比例风险回归模型(Cox proportional hazards regression models,简称Cox回归模型)来计算HR,一般会直接给出校正后的HR值及其95%可信区间。
有时,多臂研究中存在两个及以上的干预措施,但只报告相对于同一参照(如安慰剂)的相对干预效应,如一项新辅助化疗治疗壶腹周围癌术后患者的临床研究,将性别、吸烟状态、干预措施等作为调节因素纳入Cox回归模型进行分析,选取干预措施相应结果如表3所示,共分为三个治疗组,分别为观察组、氟脲嘧啶(fluorouracil)联合亚叶酸(folinic acid)组、吉西他滨(gemcitabine)组。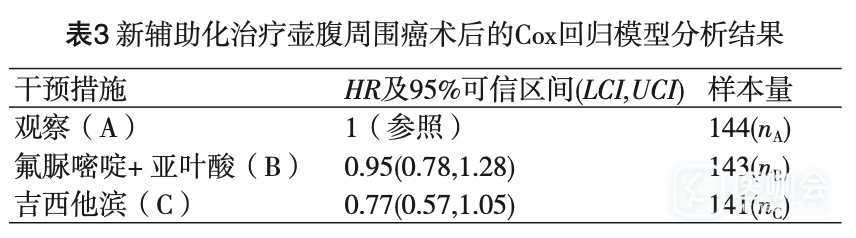
针对表3中的数据,可以按下列方法获得两两比较的效应量(如HR对数尺度)及其标准误。首先,根据Tierney法[1]分别获得B vs. A和C vs. A风险比HR对数尺度的相应标准误: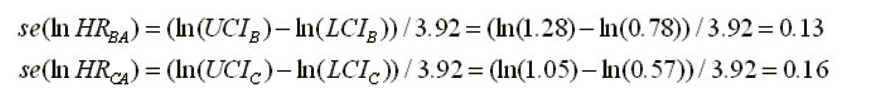
其次,根据Woods法获得C vs. B风险比的对数尺度及相应近似标准误: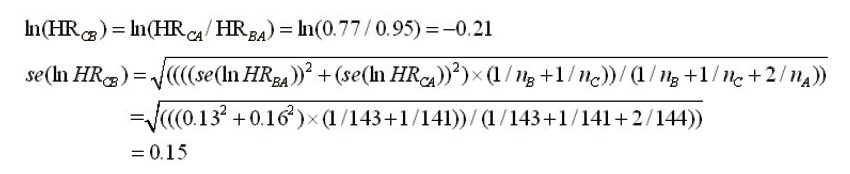
2.3 Kaplan-Meier曲线
K-M曲线法是一种用于评估风险函数的非参数方法,不需要对生存时间的分布进行特殊指定,并图示化结果显示数据的风险函数估计。如果原始研究采用K-M曲线报告了OS、PFS等生存结局,则可从中获得随时间变化的生存比例等数据。
如Guyot等建立了一种算法,可从已发表的K-M曲线中重建“伪(pseudo)”IPD,从而获得相应的HR等效应量,可用于进行经典的Meta分析或NMA。国内已有学者[2]介绍了采用图形数据提取软件(如Engauge Digitizer软件)处理K-M曲线、提取数据,并计算HR及其方差的具体操作过程,均可供参考,本文不再赘述。
2.4 二分类数据或计数数据转换
有的研究可能报告了时点生存率,但未报告获HR等其他数据,如果没有截尾值,可通过相对危险度(RR)或者比值比(OR)替代计算HR,但RR或者OR并未考虑时间因素,与HR相比丢失了一些重要的信息,故这种处理方法不作为常规选择。
新近Watkins提出了一种合并二分类数据与HR的简单方法,与Woods法异曲同工,其中也提供了二分类数据(计数或比例)转换为HR的方法:为简单起见,假设每个两臂研究中的臂为k(k=1,2),每个臂的总人数为nk,时间为t*上观察到事件发生人数为rk(t*),或比例pk(t*)=rk(t*)/nk(t*),则HR的对数尺度及相应标准误分别为:
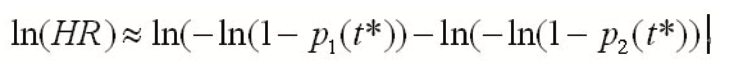
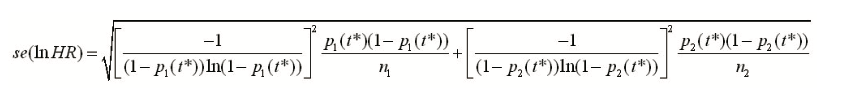










确认删除