




2026医咖会会员权益重大更新!🎁参与投票领1年基础会员>>
一、问题与数据
某呼吸内科医生拟探讨吸烟与肺癌发生之间的关系,开展了一项成组设计的病例对照研究。选择该科室内肺癌患者为病例组,选择医院内其它科室的非肺癌患者为对照组。通过查阅病历、问卷调查的方式收集了病例组和对照组的以下信息:性别、年龄、BMI、COPD病史和是否吸烟。变量的赋值和部分原始数据见表1和表2。该医生应该如何分析?
表1. 肺癌危险因素分析研究的变量与赋值
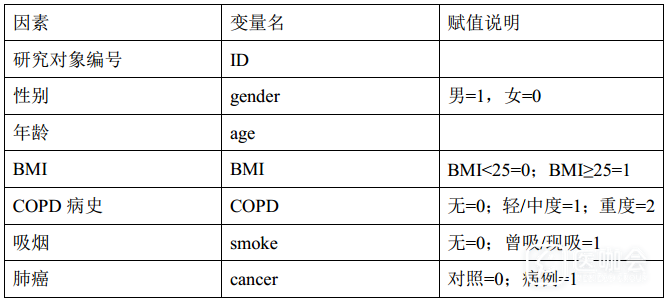
表2. 部分原始数据

二、对问题分析
该设计中,因变量为二分类,自变量(病例对照研究中称为暴露因素)有二分类变量(性别、BMI和是否吸烟)、连续变量(年龄)和有序多分类变量(COPD病史)。要探讨二分类因变量与自变量之间的关系,应采用二分类Logistic回归模型进行分析。 在进行二分类Logistic回归(包括其它Logistic回归)分析前,如果样本不多而变量较多,建议先通过单变量分析(t检验、卡方检验等)考察所有自变量与因变量之间的关系,筛掉一些可能无意义的变量,再进行多因素分析,这样可以保证结果更加可靠。即使样本足够大,也不建议直接把所有的变量放入方程直接分析,一定要先弄清楚各个变量之间的相互关系,确定自变量进入方程的形式,这样才能有效的进行分析。
表3. 病例组和对照组暴露因素的单因素比较
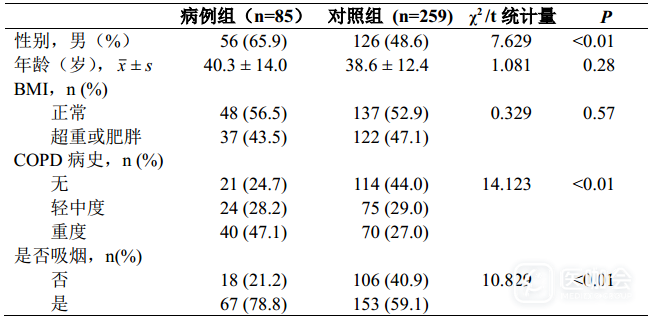
单因素分析中,病例组和对照组之间的差异有统计学意义的自变量包括:性别、COPD病史和是否吸烟。
此时,应当考虑应该将哪些自变量纳入Logistic回归模型。一般情况下,建议纳入的变量有:1)单因素分析差异有统计学意义的变量(此时,最好将P值放宽一些,比如0.1或0.15等,避免漏掉一些重要因素);2)单因素分析时,没有发现差异有统计学意义,但是临床上认为与因变量关系密切的自变量。












确认删除